
Here at Motus, we have a pretty cyclical traffic pattern. Most of the month our load is pretty even, and then for 4 days a month, our traffic goes up 10x. And when 3 of those 4 days are holidays, that 4th day is even busier. We noticed this month that our database server was having to work a little harder than usual, and so we decided to do a little query tuning exercise.
We’re huge fans of New Relic here, and it was invaluable for showing us where to start. We got a list of our most time-consuming queries and could start knocking them off. It’s very satisfying to make graphs do this:
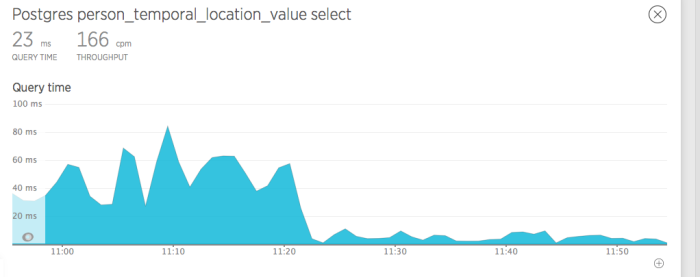 by adding one index. We went through a bunch of queries and were able to make some noticeable differences.
by adding one index. We went through a bunch of queries and were able to make some noticeable differences.
However, as we started clearing the easy ones, we started seeing queries appearing that should have been really fast. As in, queries against tables with 24 rows taking 3ms most of the time but occasionally taking 500ms. It was having the effect of making query time averages 10-15x what they should have been.
I have to give complete credit on this one to the pgsql-performance mailing list. Several posters immediately started making suggestions, and we went through a number of checks to see what was going on:
- Were the queries waiting on database locks? We changed the deadlock_timeout setting to 100ms and enabled log_lock_waits so that Postgres would tell us if queries were waiting for locks. Nothing there.
- Was autovacuum running and locking the table? We set autovacuum_log_min_duration to 0 so that we’d get notified every time autovacuum ran. Not it.
- Was the data being flushed out of the shared buffers? We were able to capture this behavior occasionally in PSQL, so we used the EXPLAIN (ANALYZE, BUFFERS) command to see if Postgres was hitting disk reads instead of shared buffer space. Nope.
- Was the OS swapping and flushing the shared_buffer to disk? No, vmstat showed no swapping.
The last thing suggested was to check the transparent_hugepage kernel setting. Apparently CentOS 6 and greater uses this feature to improve memory access, but for database servers it can actually add to CPU load. And lo, there it was – we had transparent_hugepage enabled. When I disabled it, all the sudden I got that great feeling again:
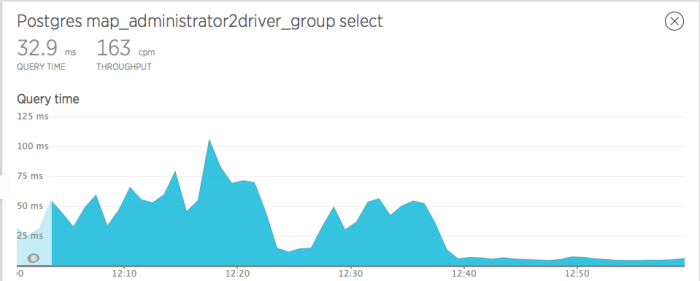
So there you have it – if you don’t have a dedicated DBA on staff, email a few and they’ll have some great things to say.
